AI Augmentation of Polymer Research and Beyond
Presentation at Louisiana State University

The Big Question
Will AI surpass human intelligence in the near future?

World models + scalable objectives will drive AI improvement
— Danijar Hafner, Google DeepMind (YouTube interview)

Silicon Valley consensus: AGI within reach in 3–5 years.
Current Reality for Polymer Chemistry
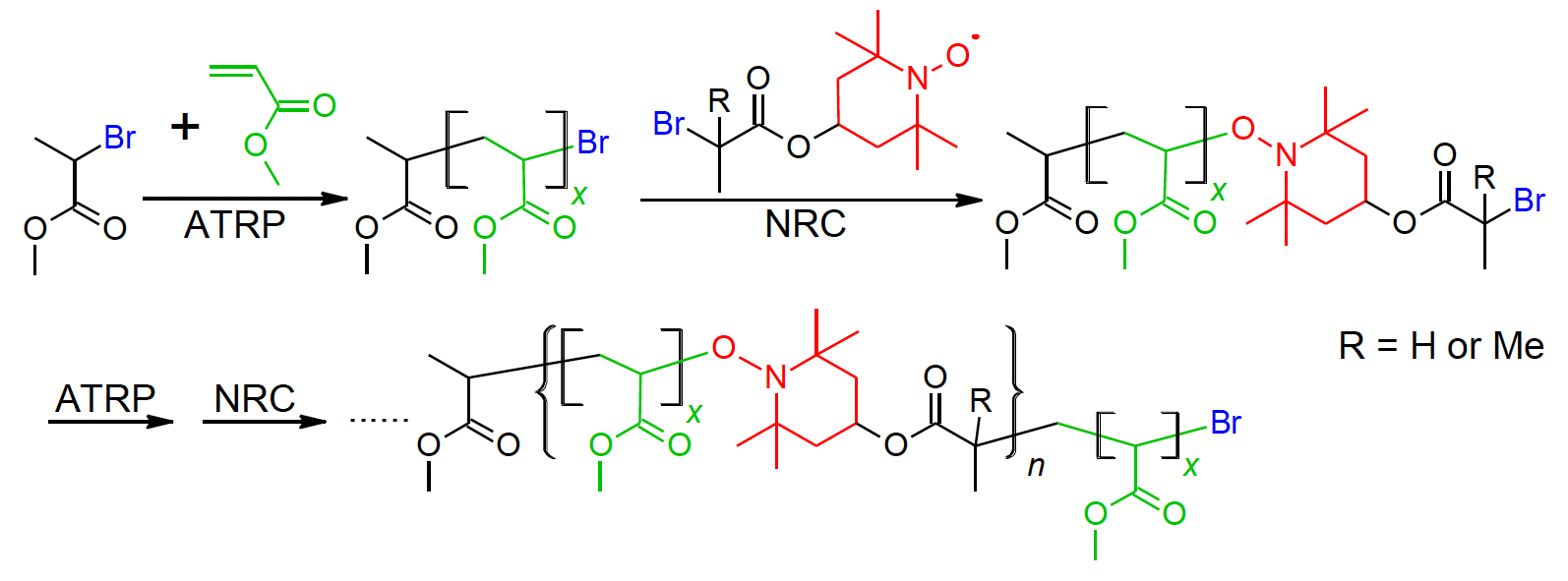
Example: Relay Polymerization (Yu Wang et al., Chem. Commun. 2021, 57, 3331–3334)
Original article scheme
AI-generated concept illustration

DOI: 10.1039/D1CC00682G
Current Reality for Polymer Chemistry
Example: Relay Polymerization (continued)
AI-generated concept illustration ✓ Good
AI-generated reaction scheme ✗ Disastrous
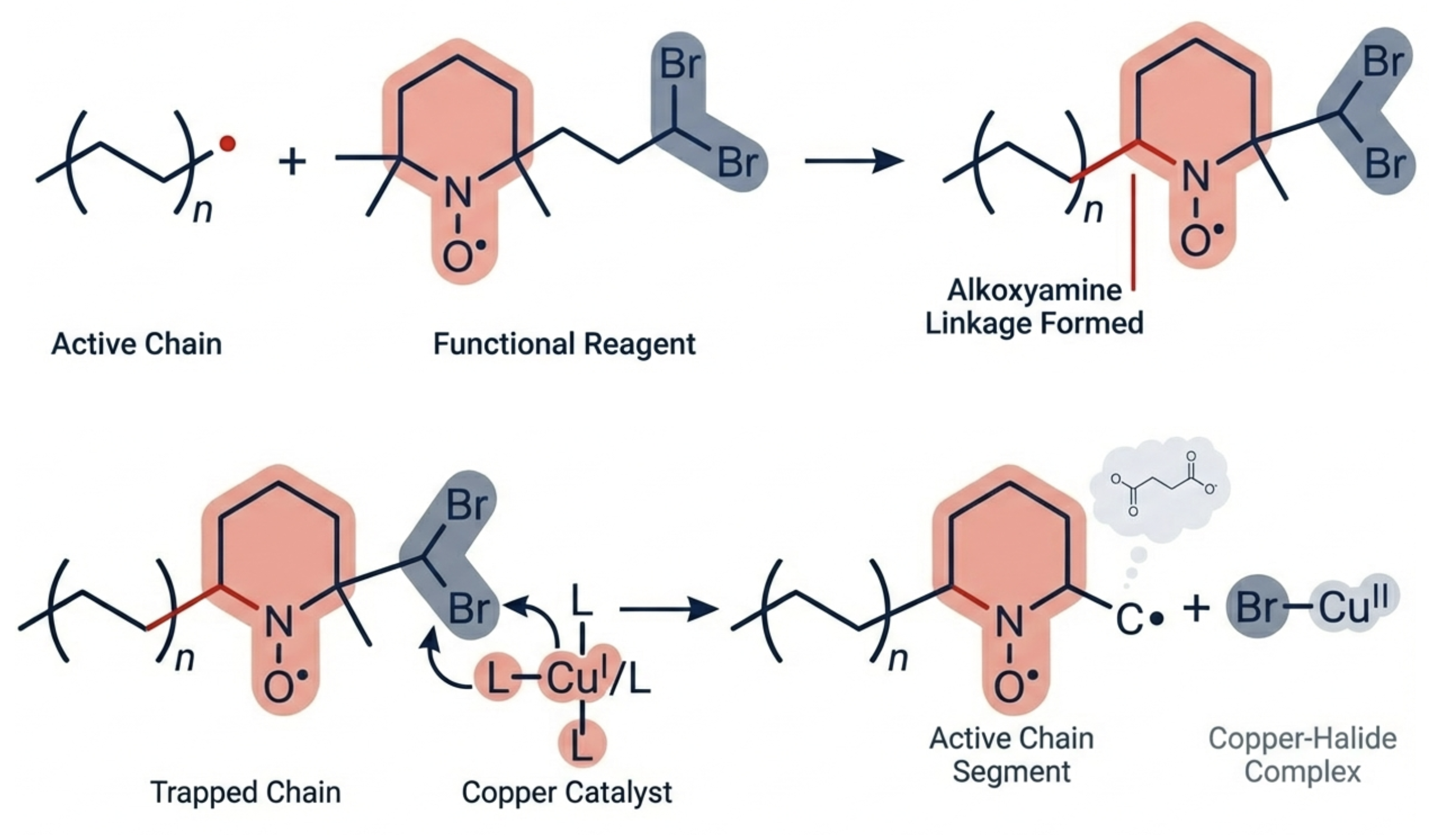
Current Reality for Polymer Chemistry
Does AI always do well on common, fundamental knowledge?
Chain-Growth Polymers
| Name | Monomer SMILES | Repeating Unit SMILES |
|---|---|---|
| Styrene | c1ccccc1C=C | *CC(*)c1ccccc1 |
| Methyl Acrylate ✗ | CC=CC(=O)OC | *CC(*)C(=O)OC |
| Acrylonitrile | C=CC#N | *CC(*)C#N |
| Methyl Methacrylate | CC(=C)C(=O)OC | *CC(*)(C)C(=O)OC |
Step-Growth Polymers
| Polymer | Monomer A SMILES | Monomer B SMILES | Repeating Unit SMILES |
|---|---|---|---|
| PET | C1=CC(=CC=C1C(=O)O)C(=O)O | OCCO | *CCOC(=O)c1ccc(cc1)C(=O)* |
| Nylon 6,6 | C(CCC(=O)O)CC(=O)O | NCCCCCCN | *NCCCCCCNC(=O)CCCCC(=O)* |
Task: generate SMILES strings for common monomers and their polymer repeating units. AI listed results for each individually, then summarized in a table. - Generated by Gemini 3.0 Pro
Current Reality for Polymer Chemistry
Does AI always do well on common, fundamental knowledge?
- AI knows styrene has two valid SMILES:
C1=CC=C(C=C)C=C1orc1ccccc1C=C. - All SMILES in the summary tables are correct.
-
One error caught: Methyl Acrylate monomer given as
CC=CC(=O)OCwhen discussed individually (crotonyl methyl ester — not methyl acrylate). Correct:C=CC(=O)OC.
The error disappeared in the later summary table. - Such mistakes may happen once in a hundred queries — too high for scientific reliance.
Current Reality for Polymer Chemistry
Example: Property trend from CH₄ → CH₃CH₃ → Polyethylene
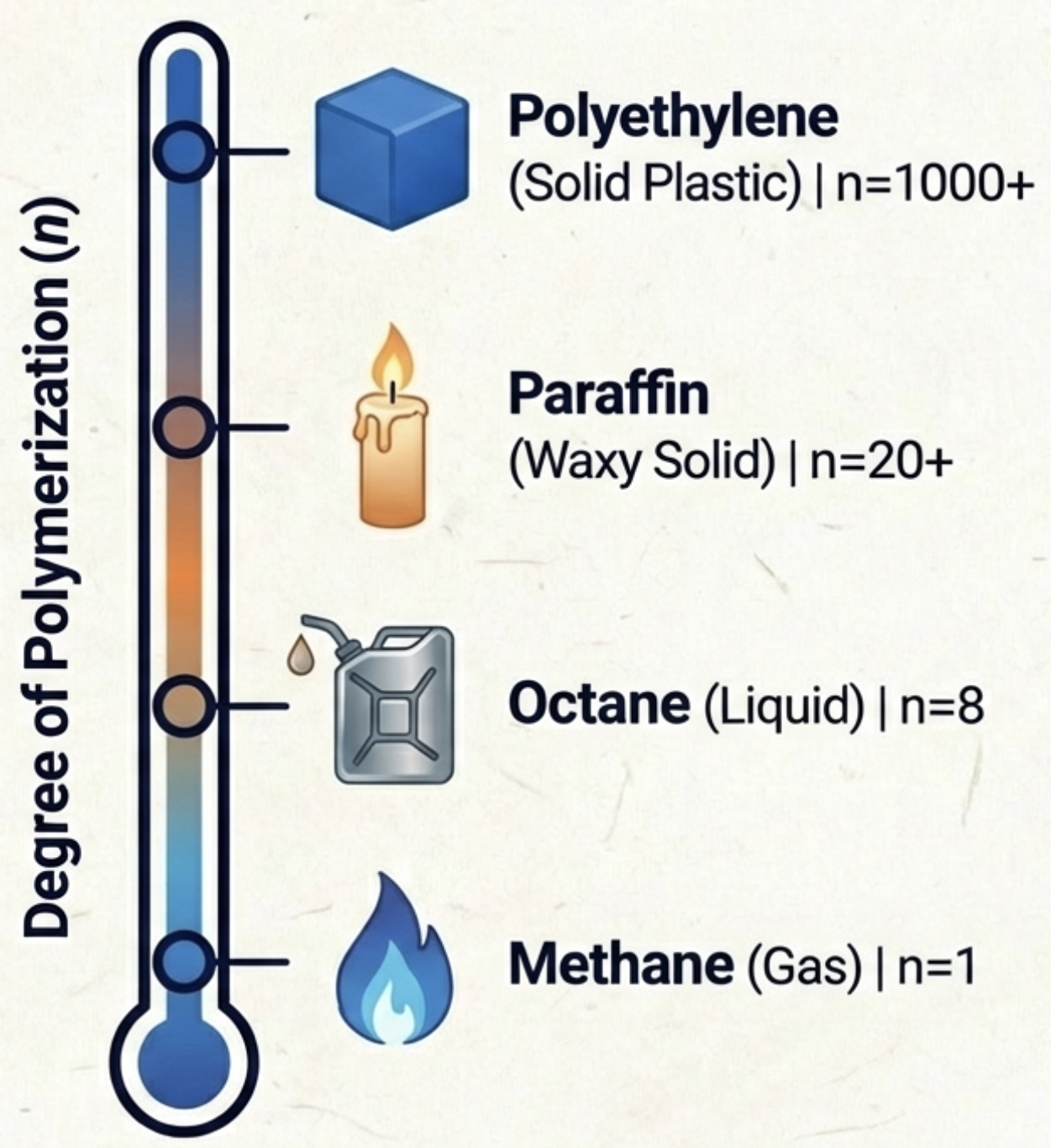
Not bad overall, but the increasing degree of polymerization is depicted like a rising temperature on a thermometer.
Current Reality for Polymer Chemistry
Example: Natural Rubber Vulcanization
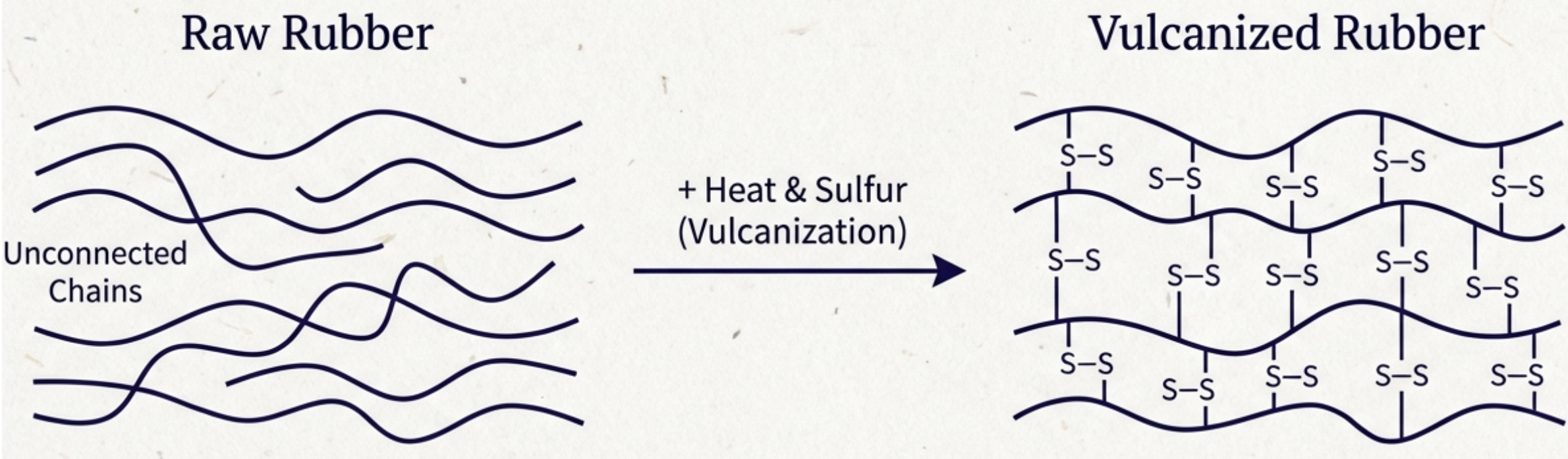
Almost correct — a relatively well-known process that AI handles well.
Current Reality for Polymer Chemistry
Example: Polymer Architecture Illustration

Good overall — except the star polymer depiction is misleading.
Current Reality for Polymer Chemistry
Example: Extended Chain vs. Random Coil Comparison

Does not resemble an extended polymer chain — the representation is incorrect.
Current Reality for Polymer Chemistry
Example: Conformation Energy Profile
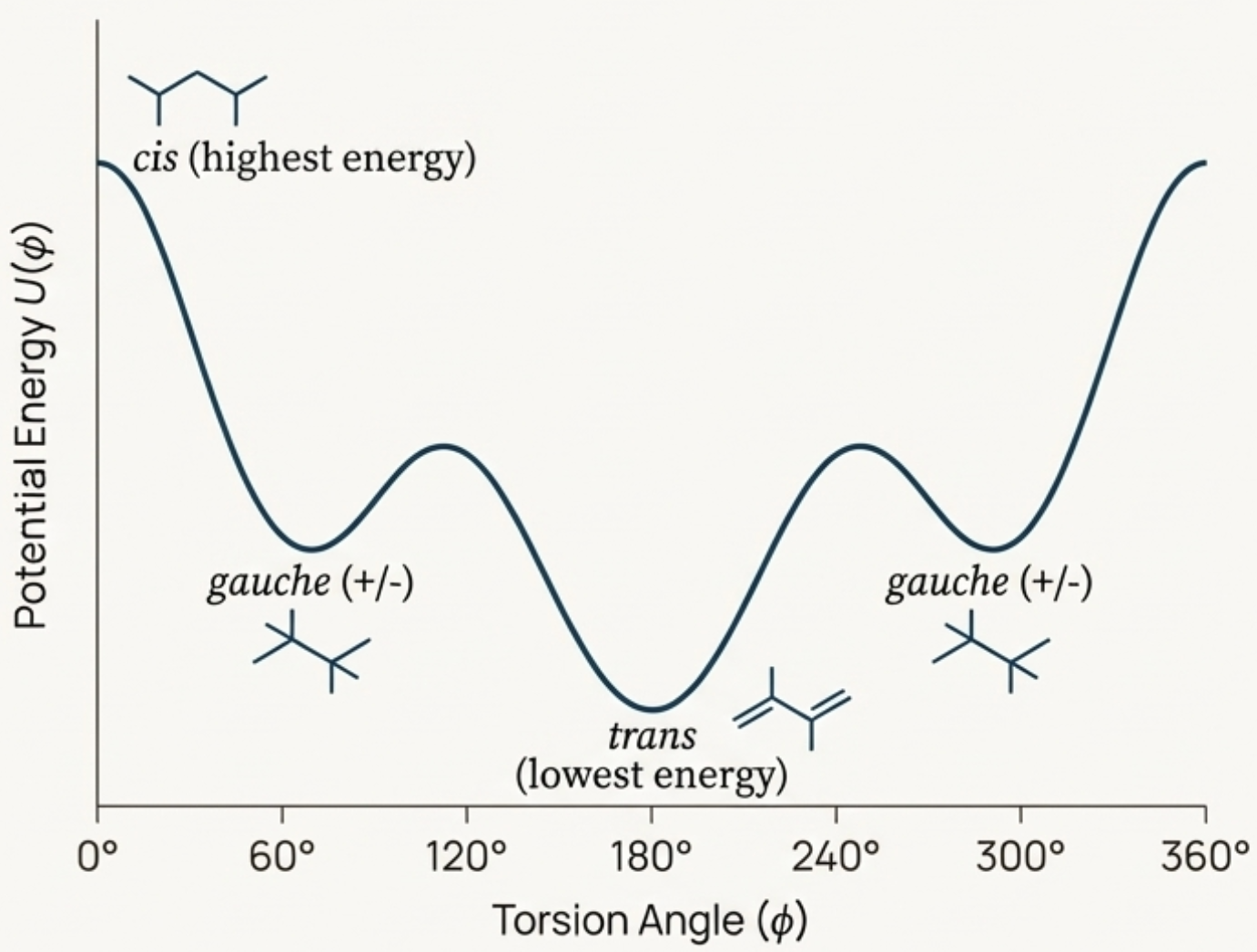
Structures depicted in the energy profile are incorrect.
Current Reality for Polymer Chemistry
Summary
- Nice illustrations sometimes — but useful only for showing final results, not mechanisms.
- Problematic fundamental structure and mechanism representations.
- Results are not consistent across queries.
- Different models would behave differently — no guarantee of reliability.
- Simple questions: generally correct, but mistakes can happen once in a hundred times — too high for scientific reliance.
Perspective: Fast Development vs. Intrinsic Limits
If AI cannot do this today, will it be solved in 6 months? 1 year? 10 years?
Optimistic View
AI is improving rapidly — these are temporary problems.
Structural View
There may be intrinsic, architectural limits that persist regardless of scale.
Knowing what AI cannot do is as important as knowing what it can do.
Thought Experiment: The Go (圍棋) Challenge
The Setup: Describe the rules of Go in plain language to a state-of-the-art general reasoning LLM. It plays against a human.
Does it win?
No. Not even close.

AlphaGo succeeded through game-specific training, not general reasoning.
Outline of the Presentation
- Introduction
- Fundamental principles of machine learning
- Application of machine learning in polymer science
- Fundamental principles of large language models
- Advanced usage of LLMs
- Perspective & Conclusions
What is AI? — The Concept Hierarchy

AGI (Artificial General Intelligence): The long-term goal, not yet achieved.
An AI Model is Just a Math Function
Classical Fit

2 parameters tuned to fit data
AI Model

Billions of parameters, same idea
Input → $f(x_1, x_2, \dots, x_n)$ → Output
Inside the Black Box
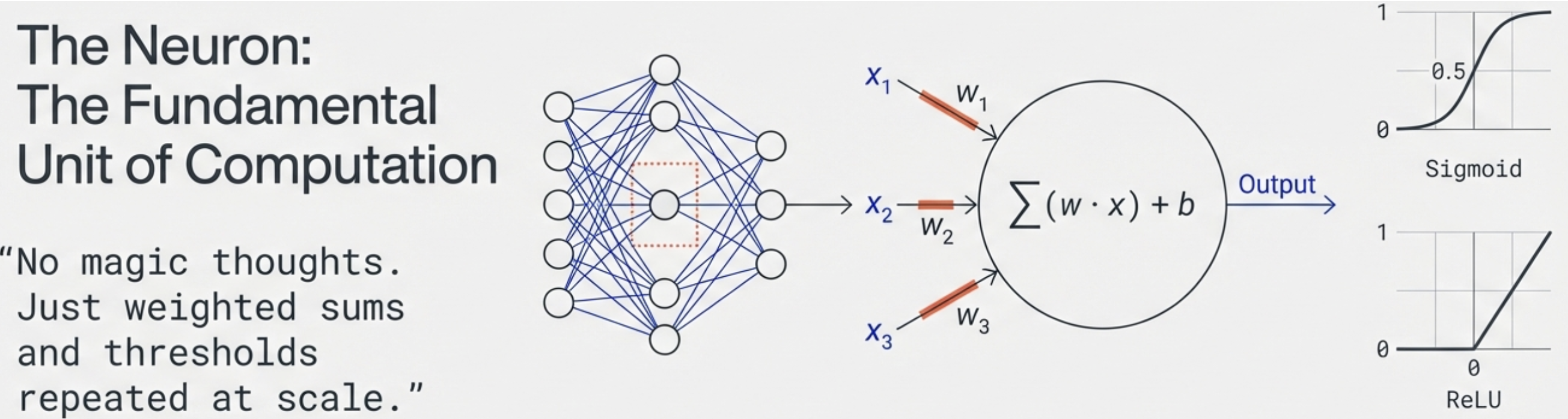
Node Calculation:
- $z = w_1 x_1 + w_2 x_2 + w_3 x_3 + b$
- $a = \text{activation}(z)$
Activation Functions:
- Sigmoid: $\sigma(z) = \frac{1}{1+e^{-z}}$
- ReLU: $\max(0, z)$
Training a Model — Finding the Best Parameters
Step 1
Feed the model labeled examples.
Measure standard solutions.
Step 2
Compare output to correct answer (compute error).
Compare instrument response to known conc.
Step 3
Nudge parameters to reduce error. Repeat.
Adjust calibration until error is minimized.
Why Scale Matters
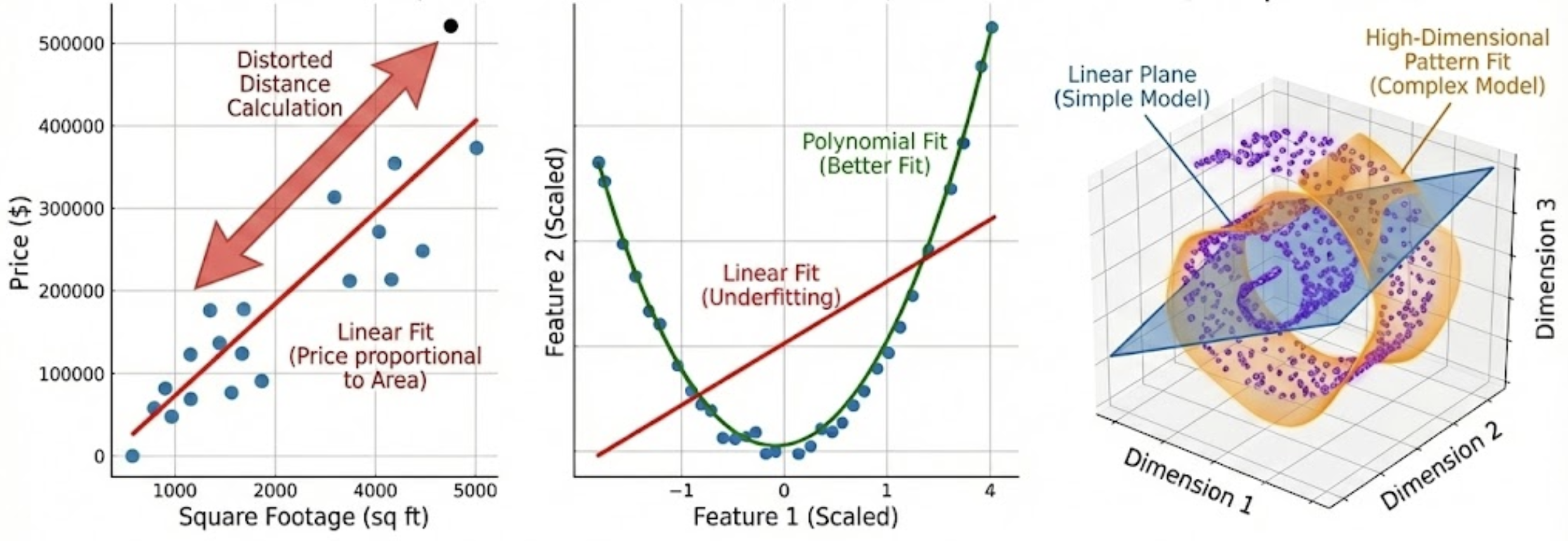
2 Parameters
Fits a straight line
~10 Parameters
Captures complex curves
Billions of Parameters
Captures language, images,
proteins
A model with "only" a few billion parameters is now considered a small language model.
Handling Multiple Vectors: CNN
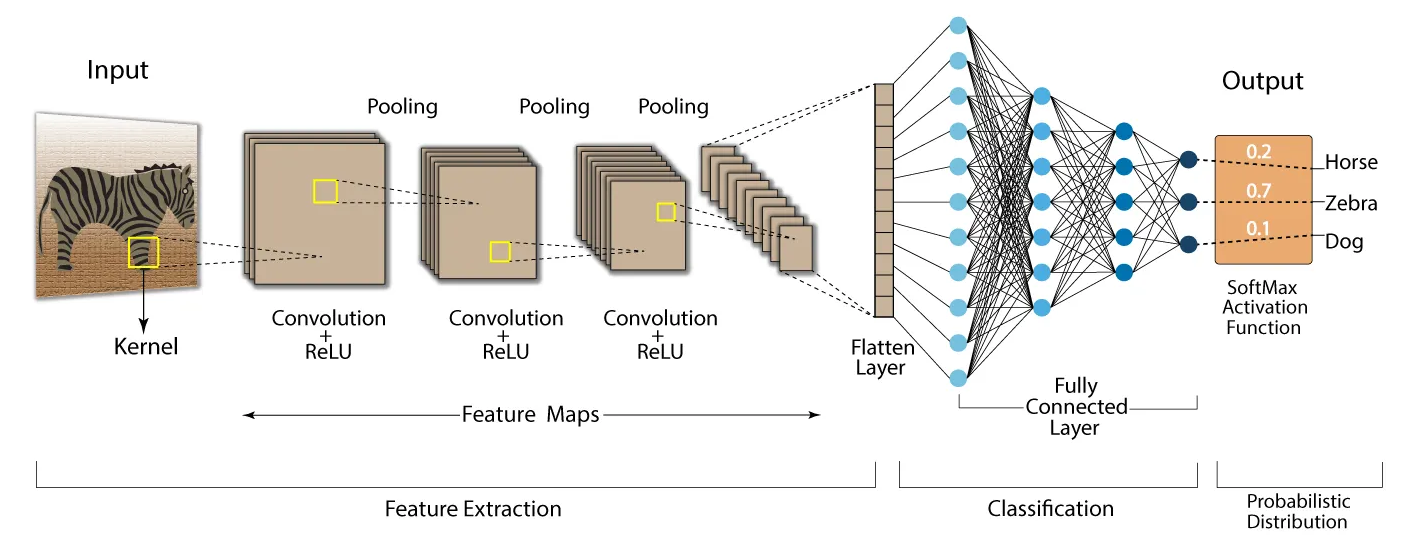
How it works:
- Input: An image is a grid of numbers.
- Filters: Small matrices slide over the image to detect patterns (edges, shapes).
- Pooling: Shrinks the image to keep only the most important features.
The Result:
- Early layers find simple lines and edges.
- Deeper layers combine them into complex shapes (ears, eyes).
- The final layer outputs a probability for classification.
What Training Tells Us About Limits
1. No Growing Memory
A model is a fixed function. Weights do not change during inference.
Input → [Frozen Model] → Output
2. Never 100% Accurate
Training minimizes error but never eliminates it.
Adversarial attacks: imperceptible noise fools the model.
3. Fine-Tuning is Risky
Fixing one behavior can silently degrade others.
Like brain surgery: fix one region, inadvertently disrupt connected functions.
4. Not Explainable
Billions of intertwined parameters give correct outputs with no interpretable reasoning path — the model cannot tell you why it gave an answer.
A black box: you can observe inputs and outputs, but not the decision process inside.
All four problems reappear in LLMs.
Adversarial Attack is Possible

The Vulnerability
By adding carefully crafted, human-imperceptible noise to an image, an ML model can be made to confidently misclassify it.
Why It Happens
The model does not "see" the way humans do. It exploits high-dimensional statistical patterns.
Connection to Limit 2
Training minimizes average error but cannot guarantee robustness at every point in input space.
Outline of the Presentation
- Introduction
- Fundamental principles of machine learning
- Application of machine learning in polymer science
- Fundamental principles of large language models
- Advanced usage of LLMs
- Perspective & Conclusions
General Aspects: What Problems Fit ML?
Suitable Problem Characteristics
- Pairwise, high-quality data: reliable input-output examples for learning
- Clear representation: information can be translated into efficient numeric forms
- Complex feature-label mapping: latent correlations are hard to hand-code
AlphaGo and AlphaFold
- Simple rules/representations: game states for Go; sequence/structure constraints for proteins
- Hard search spaces: both face enormous numbers of possibilities
- ML advantage: discovers high-value patterns where exhaustive search is infeasible
When Not to Employ ML
- Data quality is poor: noisy, inconsistent, or weakly labeled data undermines reliability.
- Data collection is prohibitively time-consuming: if high-quality data cannot be obtained at practical cost/timeline, ML is often not the right tool.
The Landscape of ML in Polymer Science
Annual ML-related publications in polymer science (2015–2025 proj.)
Types of Applications
- Predict: Structure → Property
- Generate: Target Property → Structure
- Optimize: Tune synthesis conditions
- Characterize: Extract info from data
Enabling Infrastructure: Polymer-specific representations (SMILES → BigSMILES → PSMILES) and curated databases (PolyInfo, PI1M).
Protein Structure Representation
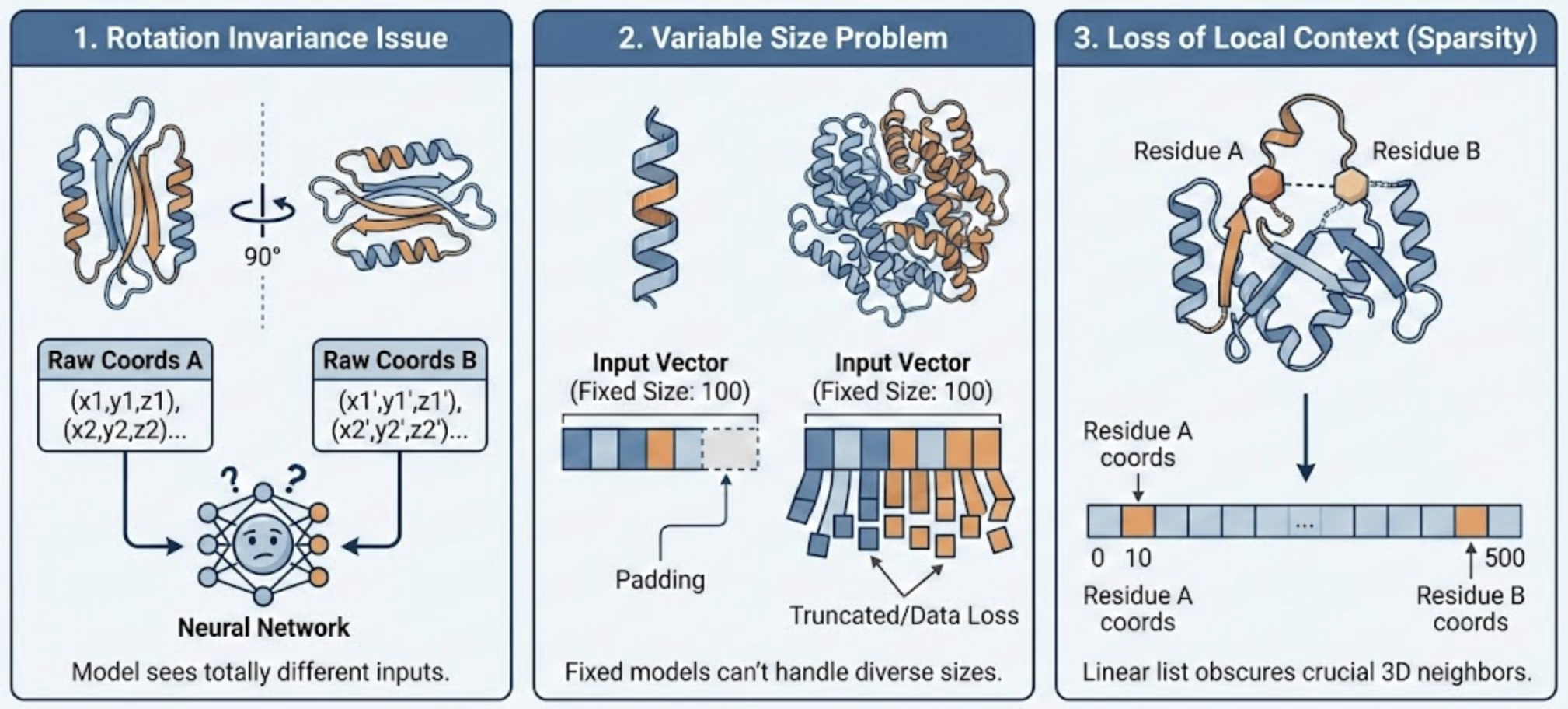
Raw 3-D coordinates fail as direct model input
Q1 — What training labels do we use?
Q2 — What numerical representation encodes 3-D structure?
Protein Structure Representation
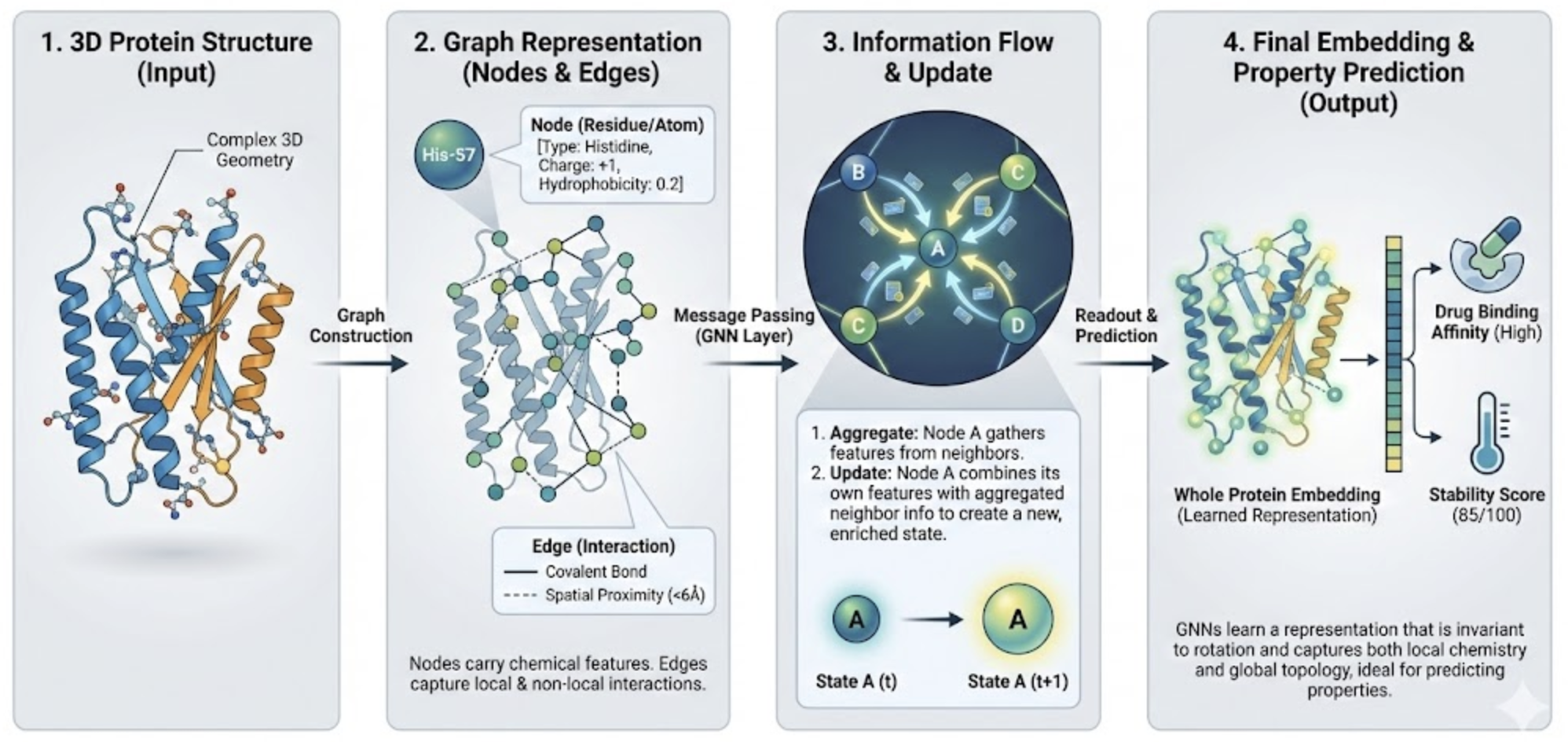
Graph Neural Network encodes protein & drug structure
Solution: Graph Neural Networks (GNN)
Finding
The model was trained with only bind/not-bind labels — binding site locations were never provided. Yet gradient/attention analysis shows the model can possibly identify the correct binding site without supervision.
Protein Structure Representation — TSR
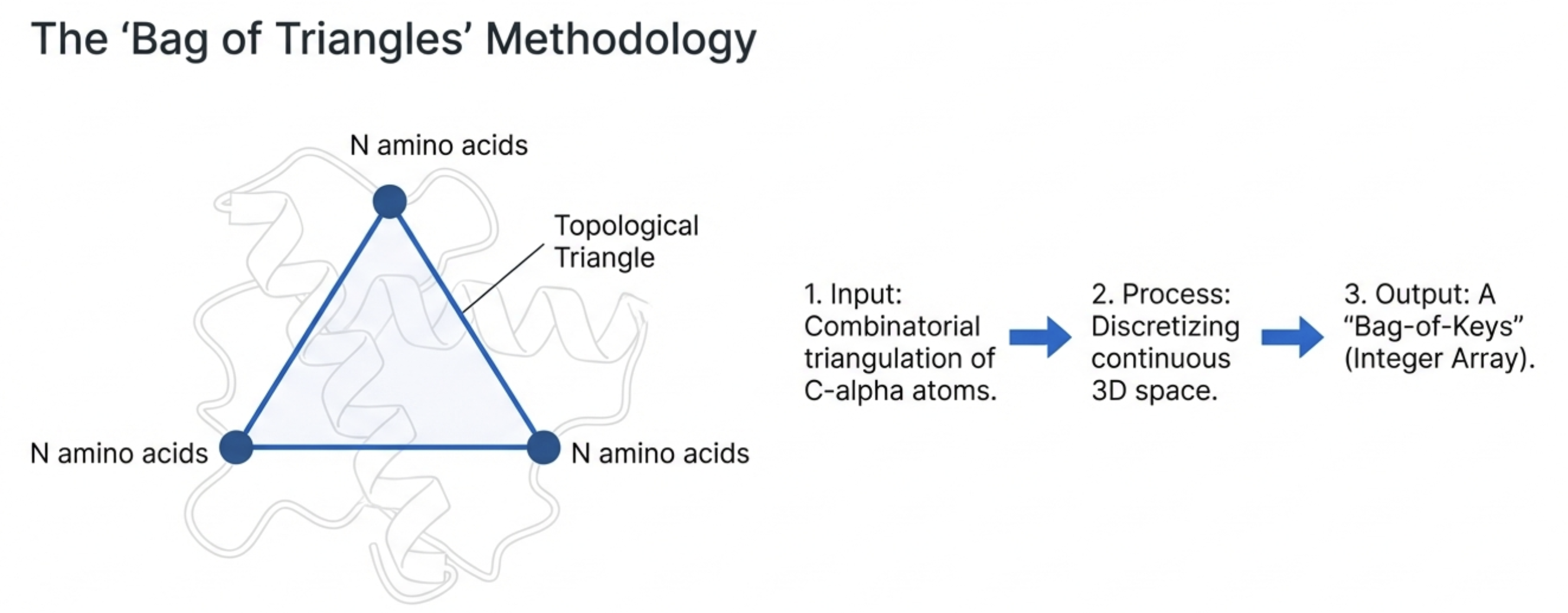
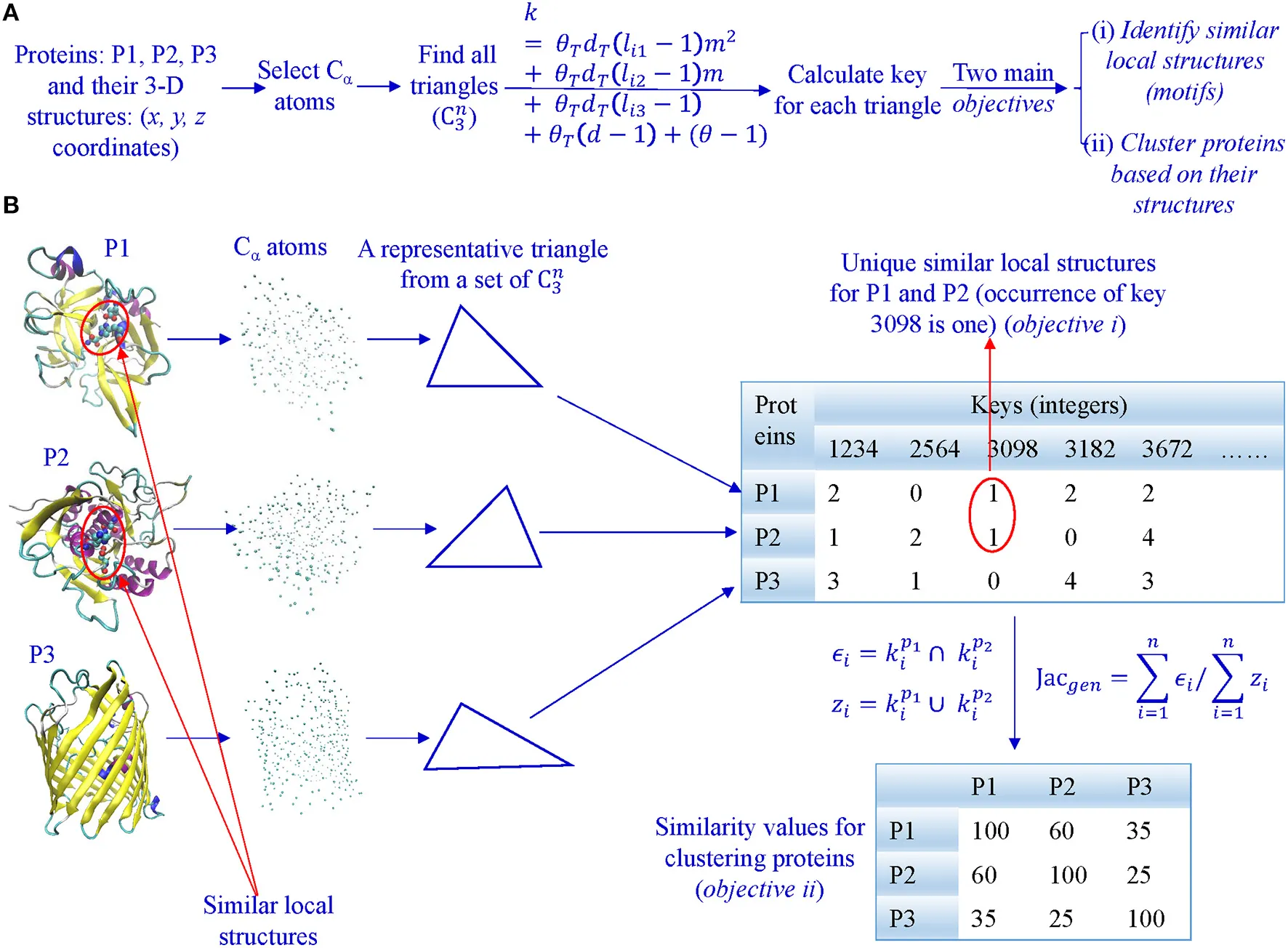
Fig. 2 — Overview of TSR-based method & key generation workflow (Kondra et al., 2021)
Every triangle of Cα atoms → one integer “key” (hover for detail)
Triangular Spatial Relationship (TSR)
Select all Cα atoms; form every possible triangle. Each triangle → integer key encoding edge lengths, Theta, and amino-acid identity. A 100-residue protein generates C(100,3) ≈ 160,000 keys; large proteins exceed 1 M. Similarity between two proteins = shared-key fraction (Generalized Jaccard). Inherently invariant to rotation & translation by construction.
Kondra et al., Front. Chem. 8:602291 (2021). doi:10.3389/fchem.2020.602291
SSE-TSR: Enriching TSR with Secondary Structure
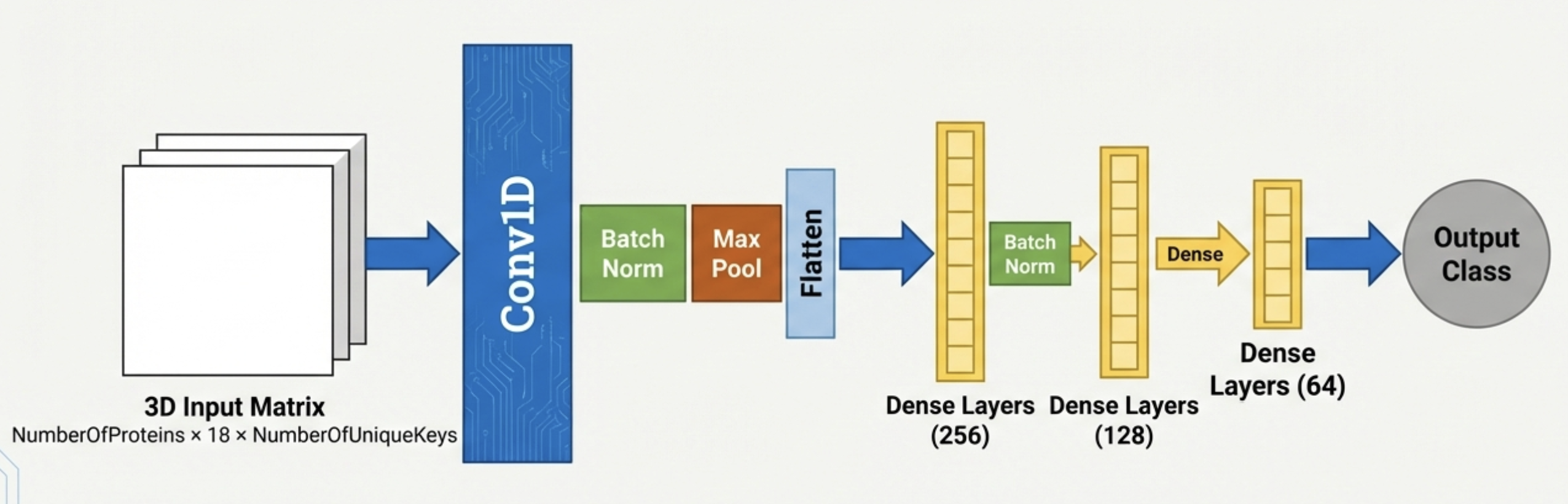
The Core Idea — A Smarter TSR Representation
Key Findings (4 benchmarks) (hover for details)
- CATH (9.2 K): 96.00% → 98.33%
- SCOP (7.0 K): 95.46% → 99.00%
- Functional-1 (7.8 K): 99.41% → 99.50%
- Functional-2 (7.2 K): 95.83% → 98.83%
Competitive with Foldseek; sparse tensor enables memory-efficient large-scale analysis.
SSE-TSR Benchmark Details
| Dataset | Size | Type | TSR Accuracy | SSE-TSR Accuracy | Δ |
|---|---|---|---|---|---|
| CATH-based | 9,200 | Structural | 96.00% | 98.33% | +2.33% |
| SCOP-based | 7,000 | Structural | 95.46% | 99.00% | +3.54% |
| Functional-1 (published) | 7,800 | Functional | 99.41% | 99.50% | +0.09% |
| Functional-2 (new) | 7,200 | Functional | 95.83% | 98.83% | +3.00% |
Model: 3-D CNN on sparse SSE-TSR tensor • Compared against baseline TSR (3-D CNN) and Foldseek • All datasets: balanced, non-redundant splits
Khajouie et al., IEEE Trans. Comput. Biol. Bioinform. (2026). doi:10.1109/TCBBIO.2026.3654047
The Two-Layer Secret of Applied ML
“Garbage in, garbage out” —
but also: genius in, genius out.
The single highest-leverage decision in any ML project is how you represent your
data.
🔬 Representation — Your Job
- Requires deep domain expertise
- Encode the physics & chemistry your model needs to see
- Raw coords → Graph → SSE-TSR: each step = a domain insight
🧩 Architecture — Like Playing Lego
- Standard blocks exist: CNN, RNN, GNN, Transformer, 3-D CNN…
- Select & combine to match your representation's geometry
- Mostly a CS problem — scientists guide the what, not the how
Takeaway: Invest your creative energy in the representation. Once the input captures the right physics and chemistry, a standard architecture will do the rest.
Ex 1: Predicting Block Copolymer Morphology


Approach: Multiclass morphology classification from processing/material variables (spin speed, annealing history, composition, substrate energy) using SVM/NN/CNN workflows, then SHAP/ridge-regression interpretation.
Findings: SVM reaches 93.75% for column/hole/island prediction; CNN-based AFM feature classification reaches ~97%; SHAP identifies additive ratio and processing knobs as dominant drivers.
Importance: moves morphology control from trial-and-error to interpretable process optimization.
Citations: Tu et al., Advanced Materials (2020), doi:10.1002/adma.202005713; R. et al., Soft Matter (2025), doi:10.1039/d5sm00335k; Lamb et al., Macromolecules (2026), doi:10.1021/acs.macromol.5c03272.
Ex 1: ML for BCP Thin Film Process Control
🧪 Input
Process variables: solvent ratio, annealing trajectory, additive type/ratio, substrate surface energy
🤖 Models
SVM/XGBoost for tabular prediction; CNN for AFM image-based morphology classification
✅ Outcome
93.75% morphology class accuracy; ~97% AFM feature classification; SHAP identifies additive ratio as dominant driver
Ex 1 — Technical Details
Technical Approach
- Input space: solvent ratio, annealing trajectory, additive type/ratio, film/composition descriptors, substrate surface energy
- Models: SVM/XGBoost for tabular prediction; NN/CNN for AFM image-based morphology classification and feature extraction
- Interpretability: SHAP and ridge regression to rank control variables
Findings & Importance
- Performance: 93.75% (PS/PMMA morphology class) and ~97% AFM feature classification
- Physics-consistent insight: additive ratio/swelling-linked variables are high-impact for final morphology/defectivity
- Practical value: enables high-throughput process window design instead of exhaustive annealing experiments
Tu et al. (2020) Adv. Mater. 10.1002/adma.202005713; R. et al. (2025) Soft Matter 10.1039/d5sm00335k; Lamb et al. (2026) Macromolecules 10.1021/acs.macromol.5c03272.
Tu et al. (2020) Adv. Mater.; R. et al. (2025) Soft Matter; Lamb et al. (2026) Macromolecules
Ex 2: AI-Engineered Enzyme (FAST-PETase)
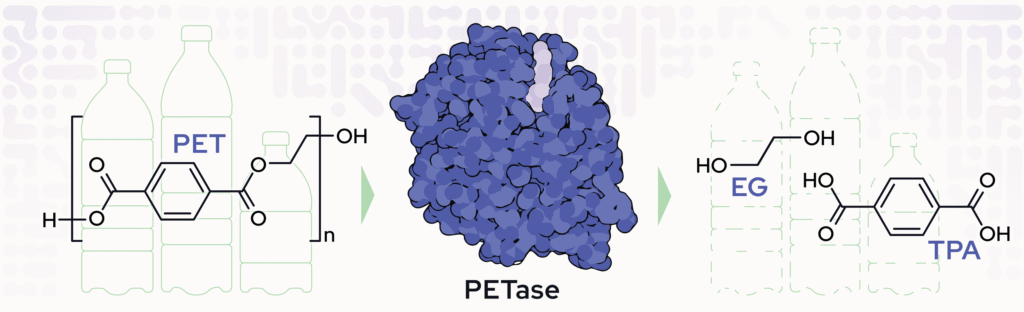
⚠️ Problem
PET plastic waste accumulates. Wild-type PETase enzymes denature at the temperatures needed for efficient depolymerization.
🤖 AI Approach
Structure-based ML proposes stabilizing mutations → wet-lab validation → combinatorial variant screening
✅ Result
FAST-PETase (5 mutations): active 30–50°C, broad pH, degrades post-consumer PET in days–weeks
Ex 2 — Technical Details
Technical Pipeline
- FAST-PETase: ML-guided mutation proposal (N233K, R224Q, S121E and 2 others), scaffold integration, wet-lab activity/stability screening
- Supporting models: XGBoost/CESR and protein-language-model pipelines for identifying plastic-degrading enzymes at scale
Findings & Importance
- Core result: broad-condition PET depolymerization; demonstrated closed-loop recycling route
- Scale-up evidence: ML classifiers achieve ~90.2% and ~89% in supporting enzyme discovery studies
- Impact: connects AI-guided biocatalyst design to practical circular-plastic workflows
Lu et al. (2022) Nature 10.1038/s41586-022-04599-z; Jiang et al. (2023) Environ. Sci. Technol. Lett. 10.1021/acs.estlett.3c00293; Medina-Ortiz et al. (2025) bioRxiv 10.1101/2025.02.09.637306.
Lu et al. (2022) Nature; Jiang et al. (2023) Environ. Sci. Technol. Lett.; Medina-Ortiz et al. (2025) bioRxiv
Ex 3: Closed-Loop Self-Driving Lab
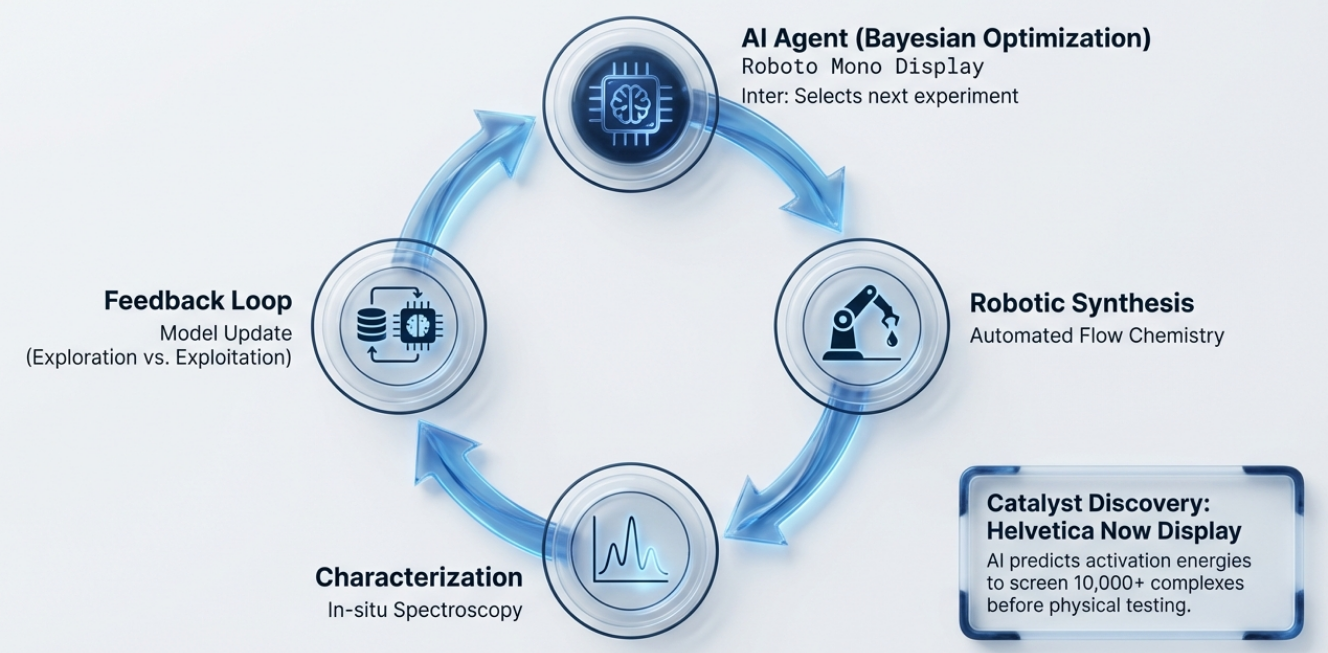
⚙️ Setup
Robotic processing + in-line characterization + Bayesian optimization — no human between cycles
🔁 How It Works
Importance-guided BO balances exploration & exploitation over a high-dimensional process space
✅ Outcome
Fast convergence to high-conductivity, low-defect films; blueprint for self-driving R&D pipelines
Ex 3 — Technical Details
Technical Approach
- Loop: propose → robotic execution → automated measurement → Bayesian model update → next experiment
- Search strategy: importance-guided Bayesian optimization to balance exploration and exploitation in high-dimensional processing space
- Role of AI: orchestration, uncertainty-aware decision making, and adaptive campaign planning
Findings & Importance
- Outcome: faster convergence to target polymer-film quality; reduced manual experimental burden
- Reliability: statistically controlled, repeatable campaign execution in autonomous mode
- Impact: blueprint for self-driving polymer R&D pipelines scaling to broader multi-agent informatics workflows
Wang et al. (2025) Nat. Commun. 10.1038/s41467-024-55655-3; Roy et al. (2026) arXiv 10.48550/arXiv.2602.00103.
Wang et al. (2025) Nat. Commun.; Roy et al. (2026) arXiv
Ex 4: Inverse Design of Recyclable Polymers
🧬 Starting Point
GA designs ROP monomers → virtual forward synthesis → polymer fingerprints. ML screens 6 properties ($T_g$, $T_d$, $\sigma_b$, $E$, $C_p$, $\Delta H_p$)
🔍 Search Scale
Surveys ~0.9M candidates in silico; fitness target: durability + recyclability for polystyrene replacement
✅ Result
>7,500 candidates hit all 6 targets; ~99.96% search cost reduction vs. exhaustive enumeration
Ex 4 — Technical Details
Technical Approach
- Design space: ring-opening-polymerization (ROP) monomer scaffolds + curated R-groups
- Generation loop: GA mutation/crossover → virtual forward synthesis (SMARTS templates) → polymer fingerprints
- Property surrogates: ML models for $T_g$, $T_d$, $\sigma_b$, $E$, $C_p$, and $\Delta H_p$ plus synthetic-accessibility screening
- Fitness: optimize durability + recyclability constraints (ceiling temp $T_c = \Delta H_p / \Delta S_p$)
Results & Caveats
- Efficiency: ~99.96% reduction vs. brute-force enumeration over billion-scale combinatorics
- Output: 7,731 candidates satisfy all six property windows for recyclable PS replacement
- Caveat: synthetic complexity remains a bottleneck for many high-performing candidates
- Takeaway: AI narrows the lab funnel to a tractable shortlist for experimental validation
Atasi, C.; Kern, J.; Ramprasad, R. J. Chem. Inf. Model. 2024, 64 (24), 9249–9259. doi:10.1021/acs.jcim.4c01530.
Atasi et al. (2024) J. Chem. Inf. Model. 64, 9249–9259. doi:10.1021/acs.jcim.4c01530.
Outline of the Presentation
- Introduction
- Fundamental principles of machine learning
- Application of machine learning in polymer science
- Fundamental principles of large language models
- Advanced usage of LLMs
- Perspective & Conclusions
Part A — Training
What Pairwise Dataset Should We Use?
The self-supervised trick
Question for the audience: A neural network needs pairwise data — input and correct output. What could those pairs be for language?
Answer — mask & predict: Take any sentence, remove some tokens, predict what was removed.
"Polystyrene ______ in toluene at room temperature." → dissolves
Every paragraph on the internet is automatically a labeled training example — no human annotation needed.
Critical caveat: The training objective is linguistic plausibility, not truth. The model minimizes loss equally well by writing "I do not know" — or by confidently hallucinating.
Part A — Training
Pre-training Gives Coherence, Not Quality
RLHF and Alignment
① Pre-training
Train on hundreds of billions of tokens. Objective: predict the next token. Outcome: learns grammar, facts, reasoning patterns — but no sense of helpfulness or safety. Would complete "How do I build a bomb?" with the same fluency as "How do I make bread?"
② RLHF — Reinforcement Learning from Human Feedback
Human raters compare pairs of responses and mark which is better. Model is fine-tuned toward preferred responses. Outcome: helpful, clear, appropriately cautious.
③ Alignment
Humans flag prompts the model should refuse. Model learns boundaries. Outcome: safety guardrails.
Part A — Training
Revolution of LLMs
From curiosity to essential tool in three years
Capacity improvements
- Parameters: 175 B → ~1 T+
- Context: 4 K → 1 M+ tokens
- Multimodal inputs
- Mixture-of-Experts (MoE)
Application strategy improvements
- System prompts & chain-of-thought
- Few-shot examples in context
- RAG — live database access
- Tool use & agentic pipelines
In 2026, we do not rely on a single LLM in isolation. Instead, we orchestrate a combination of models, external resources, and tools, guided by carefully designed system prompts. This orchestration is what makes them appear so intelligent and capable. Yet even the most advanced 2026 models still commit surprisingly basic errors — a consequence rooted in the fundamental principles of how LLMs are trained.
Part B — Architecture
Why Not Just Assign One Number Per Word
and Use a Basic Neural
Network?
One integer per word
cat=1, dog=2, polymer=3, solvent=4…
Theoretically works — a large enough network can learn the mapping.
But: integers carry false structure. Math treats 1 and 2 as "close" — but cat and dog are not closer to each other than to polymer in any meaningful sense. The model wastes capacity fighting irrelevant numerical noise.
Plain feedforward network
Theoretically works — universal function approximator in principle.
But: processes positions independently — no direct connection between distant words; parameters explode with sequence length; must re-learn the same patterns at every position. Extraordinarily wasteful.
Takeaway: Both approaches are not wrong in principle. The motivation for embeddings and attention is efficiency — the naive approaches cannot scale to the sizes needed to be useful.
"A titration technically works whether you use a burette or a firehose — but only one is practical."
Part B — Architecture
From Words to Numbers
Tokenization and Embeddings
Step 1 — Tokenization (sub-word fragments)
"Polystyrene dissolves in toluene"
Poly │ sty │ rene │ dis │ solves │ in │ to │ lu │ ene
Each fragment → an integer ID. The model processes numbers, not letters.
Step 2 — Embedding (integer → dense vector)
Each token ID maps to a vector of hundreds or thousands of numbers. Similar meanings cluster in this space — "polymer" and "macromolecule" land near each other; "polymer" and "Tuesday" do not.
Famous example: vector("king") − vector("man") + vector("woman") ≈ vector("queen") — the model was never told this; it emerged from training statistics.
This geometric encoding of meaning — meaning as spatial proximity — is the foundation on which everything else in an LLM rests.
Part B — Architecture
The Problem Attention Solves
Words mean different things in different contexts
How should a model know what "it" refers to?
"The polymer dissolved because it is hydrophilic."
→ "it" refers to the polymer
"The polymer dissolved in water because it is a good solvent."
→ "it" refers to water
Identical grammatical structure — opposite referent. A plain feedforward network processes each position independently with no mechanism to connect "it" to "polymer" or "water" across the sentence. This is exactly what attention was designed to solve.
Part B — Architecture
The Attention Mechanism
Every token looks at every other token
Attention matrix — "who should I attend to?"
| The | polymer | is | soluble | |
|---|---|---|---|---|
| The | ◑ | ◌ | ◌ | ◌ |
| polymer | ◌ | ● | ◑ | ◑ |
| is | ◌ | ◑ | ● | ◑ |
| soluble | ◌ | ●● | ◑ | ● |
"soluble" strongly attends to "polymer" (dark cell)
"Like a chemist reading a paper: when you see 'yield was low,' your attention jumps back to the reaction conditions. Attention — formalized as math."
The formula
In plain English: compute a relevance score between every pair of tokens; normalize to sum to 1; take a weighted average.
$$\text{Attention}(Q, K, V) = \text{softmax}\!\left(\frac{QK^\top}{\sqrt{d_k}}\right) V$$
Q = Query ("what am I looking for?")
K = Key ("what do I contain?")
V = Value ("what info do I provide?")
Q, K, V are computed from the same input using ordinary weight matrices — no new math beyond Topic 2.
Part B — Architecture
The Transformer
Stacking attention into a deep architecture
One Transformer Block (repeated ×N)
Scale in practice
- GPT‑4 has ~96 of these blocks
- Multi-head: several attention operations in parallel — each focuses on a different relationship type
- Feed-forward sub-layer = Topic 2 network applied per-token
Architecture: introduced 2017, essentially unchanged today
All "progress" since 2017 = more layers · more data · more compute · better training — not a new design.
⚠ Notice: As long as the Transformer architecture remains fundamentally unchanged, all intrinsic limits of LLMs will not be eliminated — only mitigated by scale and better training strategies.
Part B — Architecture
Putting It All Together
Embeddings, attention, and Transformer are efficiency strategies — not new science
Ingredients from Topic 2
- Weighted sum of inputs
- Activation functions
- Stacked layers
- Minimize error on training data
Where each appears in a Transformer
- Token embedding = weight matrix lookup
- Attention scores (QKᵀ) = weighted sums in parallel
- Softmax ≈ normalized Sigmoid
- Weighted sum of V = standard weighted sum
- Feed-forward sub-layer = Topic 2 network per token
- Stack N blocks = depth
Key message: Each component is a smart engineering strategy to train a better model with far less computation and data. The underlying principle is identical to one-integer-per-word + plain neural network. The Transformer achieves the same thing orders of magnitude more efficiently.
"Like assembling a house from bricks, windows, and beams — nothing fundamentally new, just a more efficient structure."
Part C — Generation
How an LLM Generates Text
Token by token, step by step
Input: "What is the capital of France?"
→ model → "Paris" (82%) → append
→ model → "." → append
→ model → [stop] → halt
Probability at one step
"Generation is a repeated lottery — the most probable ticket usually wins."
Key facts
- One full forward pass through all Transformer layers per token
- ~50,000-token vocabulary at each step
- Model samples — does not always pick the top token
- Two runs on the same prompt → slightly different outputs
Part C — Generation
An LLM Has No Understanding
But its distribution contains everything
The uncomfortable truth
The token-by-token lottery has no understanding behind it. The model samples "Paris" because that token statistically follows "capital of France" billions of times in training. It has no concept of France, no knowledge that Paris is a city.
"An LLM is a probability machine over tokens."
The surprising consequence
Trained on essentially all human-written text, the model's distribution spans the full space of plausible human responses. For any prompt, the correct answers, the helpful answers — and also the wrong, harmful, absurd ones — are all somewhere in that distribution.
AI companies did not make the model smarter — they developed strategies to steer sampling toward the good part of the distribution.
Distribution zones: helpful / correct plausible but wrong hallucination harmful
Post-training (RLHF, alignment, system prompts, chain-of-thought…) steers the sampling cursor toward the helpful/correct zone — but never eliminates the others.
"The model is not getting smarter — it is being steered."
Part D — Intrinsic Limits & Powers
Appearance vs. Reality
The gap between experience and mechanism
| What it looks like | What is actually happening |
|---|---|
| ChatGPT remembers our previous conversations | Every session re-reads a text summary; no model weights change |
| AI reasons through hard problems step by step | Probability-weighted token sampling at every step |
| AI knows an enormous amount about everything | Frozen snapshot of training data; nothing learned since cutoff |
Understanding the gap is not pessimism — it is how you use AI effectively. Each of these will be unpacked in the slides that follow.
Part D — Intrinsic Limits & Powers
"ChatGPT Remembers Me"
No real memory — just text replay
What users experience
Chat interface recalls topics from last week; seems to know your past preferences and build on previous conversations.
What actually happens
A "Memory summary" text file outside the model is prepended to every new session. The frozen model reads it — it does not remember anything.
Consequence
"Memory" is bounded by context window. Long sessions become unreliable as early facts compete with later text for attention.
Callback from Topic 2, Limit 1: Model weights are frozen. One input → one output. Always.
ChatGPT "memory" is a feature of the application layer, not the model. Continuity across sessions is only as reliable as those external summaries.
Part D — Intrinsic Limits & Powers
"AI Can Reason Through Hard Problems"
Probability dressed as logic
The impressive case ✓
Complex organic synthesis planning → correct, structured multi-step answer.
Seen many times in training data → high-confidence token patterns.
The embarrassing failure ✗
"Count the letter 'r' in 'strawberry'" → wrong.
Counting requires a deterministic sequential scan — not a next-token-prediction task.
The inconsistency ✗
Same math question, slightly different phrasing → two different numerical answers.
No internal state. No logical verification. Each response is freshly sampled.
"The model cannot distinguish between 'I know this' and 'I am generating plausible text about this.'"
In chemistry: fluent, plausible-sounding reaction mechanisms are not the same as correct reaction mechanisms.
Part D — Intrinsic Limits & Powers
Frozen Knowledge and the Cutoff Wall
"What is tomorrow's weather in Baton Rouge?" → needs real-time data
"Explain a board game invented after the cutoff" → any response is fabricated
"What did the latest JACS issue publish?" → named papers may be hallucinated
Workaround: External tools (web search, databases) connect the frozen model to live information — but these are scaffolding around the model, not changes to the model itself.
Part D — Intrinsic Limits & Powers
Hallucinations — Confident, Fluent, and Wrong
Why hallucinations are inevitable (not bugs)
The model's only job is to produce the statistically most plausible next token. It has no mechanism to fact-check its own outputs and cannot distinguish what it knows from what it is generating.
"The model does not know it is wrong."
Polymer chemistry examples
- Chemical structure with an impossible bond (wrong valence on carbon)
- Citation: real author, real journal, plausible title — the paper does not exist
- Property table with one physically impossible synthesis temperature — surrounded by correct values
Callback from Topic 2 Limit 2: the model learned statistical patterns, not ground truth. The fake citation is particularly insidious — it looks exactly like a real reference and passes casual review.
Part D — Intrinsic Limits & Powers
Detail Loss in Long Contexts
Context window (filled left to right):
As the gray expands, the green (key facts) competes for attention — and loses.

Context window ≠ working memory. Having read something and reliably using it are different things. Long contexts also amplify hallucinations. Sometimes carefully chunked RAG is better than blind context stuffing.
Part D — Intrinsic Limits & Powers
The Powers — What LLMs Do Genuinely Well
Language understanding & summarization
Condense large volumes of text rapidly and accurately. Identify key arguments, themes, and conclusions across hundreds of documents in seconds.
Pattern recognition across a corpus
Identify recurring themes, terminology, and methodological patterns across thousands of papers — impossible to do manually at scale.
Structured task execution when well-guided
Given explicit instructions, extract structured information, fill templates, follow multi-step workflows with high consistency.
Plain-language programming
Translate clearly described logical tasks into working code — anyone can automate complex processes without formal programming training.
Common thread: LLMs excel when answers can be assembled from patterns in language. They struggle when a task requires a deterministic procedure outside the domain of token prediction.
Part D — Intrinsic Limits & Powers
Implications — Where Human Expertise Remains Essential
| AI automates or augments | Human expertise remains essential |
|---|---|
| Literature search and summarization | Deciding which questions are worth asking |
| Extracting structured data from text | Designing the extraction schema and validating outputs |
| Drafting text, code, protocols | Verifying chemical correctness and logical soundness |
| Identifying patterns across reports | Interpreting whether patterns reflect reality or artifacts |
| Executing defined multi-step workflows | Designing those workflows and catching edge cases |
"Not the end of programming, but the beginning of programming in plain language. Human judgment, domain expertise, and critical evaluation remain the irreplaceable component."
Outline of the Presentation
- Introduction
- Fundamental principles of machine learning
- Application of machine learning in polymer science
- Fundamental principles of large language models
- Advanced usage of LLMs
- Perspective & Conclusions
Advanced Usage of LLMs
Limits are real — but so is capability.
What modern LLM agents can do
- Use external tools and execute command-line workflows
- Write/debug code and automate multi-step pipelines
- Follow explicit logical instructions with high consistency
When these capabilities are pipelined and automated, they become powerful tools for scientific research.
Message: The right strategy is not blind trust or rejection — it is controlled deployment.
Mission and Success Criteria
Mission
Convert large volumes of polymer-science literature into a structured, queryable knowledge database.
Accurate
Structures, values, and citations are correct.
Consistent
Same logic gives stable outputs across reports.
Complete
No key synthesis, property, or context is missed.
Unconstrained chat-style usage rarely meets all three criteria at once.
Two Routes: Training vs Context Engineering
Approach A: Task-specific model training
- High precision for narrow tasks
- Expensive and slow to update
- Inflexible after deployment
Approach B: Context engineering ✓
- Model-agnostic and future-proof
- Fast iteration through text instructions
- Scales to complex agent workflows
This talk focuses on Approach B: explicit instructions, schema contracts, and feedback loops.
Evidence: How Well Do LLMs Follow External Instructions?
CL-Bench (Dou et al., Feb 2026 · arXiv 2602.03587) — 500 expert-crafted contexts, 1,899 tasks, 31,607 rubrics
What "context learning" means
Given a self-contained document (manual, legal code, SDK, lab protocol), can the model learn the new knowledge it contains and apply it to solve tasks — without relying on pre-training?
This is exactly what happens when you give an LLM a set of Agent Skills instructions.
Benchmark results (10 frontier models)
- Average task solve rate: 17.2%
- Best model (GPT-5.1): 23.7%
- Hardest category (inductive / simulation): ~11%
- Rule-following tasks (legal & regulatory): up to 44%
Primary failure modes (% of errors)
- Context ignored: 55 – 66 %
- Context misapplied: 60 – 66 %
- Format / instruction violated: 33 – 46 %
CL-Bench: Key Takeaways & Perspectives
What helps
- Explicit, structured rules → higher solve rate (legal & regulatory: up to 44%)
- Higher reasoning effort → modest +2.5% gain
- Deductive application of provided rules outperforms inductive discovery
What still fails
- Long contexts: performance drops steadily with length
- Inductive reasoning from data (~11% solve rate)
- Fine-grained instruction adherence (format, exact labels)
- Passing instruction-following benchmarks ≠ succeeding here
Path forward
- Context-aware training data to reduce context neglect
- Curriculum learning: simple → complex tasks
- Architectural memory for deep context retention
- Synthetic rubric generation for feedback
Implication for this work: context engineering with explicit Agent Skills directly targets the dominant failure mode — context neglect. Structured schemas, validation loops, and clear rule documents are not over-engineering; they are the evidence-based answer to what unconstrained LLMs cannot reliably do on their own.
Context Engineering and Agent Skills

Agent Skills
- Plain-text rule documents
- Portable across LLMs
- Iterative updates
Framework
- Input/output schema
- Validation loops
Practical proof: this approach already drove automated generation of study guides, slides, and exam PDFs using structured rule sets.
Practical Proof-of-Use: Prior Implementations
This is not a concept-only proposal — it has already worked in real workflows.
Rule-based Structure Handling
Chemical structures and math expressions handled via explicit Agent Skills rules — not left to LLM guessing.
Standardized Output Templates
Schema-driven extraction ensures consistent field coverage across different papers and report styles.
Automated Document Generation
Study guides, slide decks, and exam PDFs generated automatically from structured pipeline output.
Practical Proof-of-Use: Example 1
Rule-based handling for chemical structures and mathematical expressions
showing correct handling of SMILES, reaction schemes, and equations]
Practical Proof-of-Use: Example 2
Automated generation of study guides, slide decks, and exam PDFs
(study guide page, slide thumbnail, exam PDF excerpt)]
Key Innovation: Graph-Based Representation

Problem: Ambiguity
“Polymer brush” = side-chain rich vs. surface grafted?
Solution: Graph
- Nodes = Components
- Edges = Linkages
- Result = Machine Queryable
Conceptual Reconstruction Workflow

1. Extraction
Synthesis, structures→graphs, properties, citation intent.
2. Search & Filter
Combine keywords, concepts, and citation networks.
3. Database
Structured, validated, cross-referenced format.
Query Layer: Graph RAG + Agentic RAG

Graph RAG
Traverse relations: "Find structurally similar polymers."
Agentic RAG
Decompose & Synthesize: "Trace evolution of synthesis."
Example: "Compare thermal stability characterization methods across all reported polyimides."
Section Summary: LLMs in Controlled Workflows
LLMs are most powerful when integrated as controlled components in a validated scientific workflow — not as unconstrained chat assistants.
What this section showed
- Agent capabilities are real and substantial
- Context engineering outperforms prompt guessing
- Agent Skills make pipelines portable and maintainable
- Graph representation resolves structural ambiguity
- Graph RAG + Agentic RAG enable deep scientific queries
Leading to Section 6
- How does this compare to manual or keyword-only curation?
- Is this framework applicable beyond polymer science?
- Broader perspectives and conclusions
Outline of the Presentation
- Introduction
- Fundamental principles of machine learning
- Application of machine learning in polymer science
- Fundamental principles of large language models
- Advanced usage of LLMs
- Perspective & Conclusions
Comparison of Literature Curation Approaches
| Approach | Pros & Cons |
|---|---|
| Manual search & curation | Thorough but weeks/months of effort; limited scope; human inconsistency. |
| Automated keyword search | Fast but shallow; massive unfiltered output; no conceptual understanding. |
| AI-augmented structured workflow | Rapid, concept-aware, structured output with built-in error-checking and cross-report analysis. |
Broader Applicability
Domain-agnostic: The same framework applies to any experimental science field by simply swapping the Agent Skills documents.
LLM-agnostic: The same set of Agent Skills works with any advanced LLM — GPT, Claude, Gemini — and produces consistent, reproducible results.

Conclusions
AI will not replace human intelligence, but it will fundamentally augment how we process information and design materials.
- Understand the limits: AI is probabilistic, not logical. It lacks true memory and reasoning.
- Harness the power: Use context engineering and Agent Skills to guide LLMs.
- The Future: A structured, accurate, and complete database of scientific knowledge, queryable from any angle.
Acknowledgments
Funding
This work is supported by the National Science Foundation under Award NSF-2142043.
Project
OVESET — Open Virtual Experiment Simulator Education Tools for Polymer Science Education oveset.orz.how
Special Thanks
GitHub Copilot served as an indispensable AI collaborator throughout this project — contributing to code development, data analysis pipelines, and scientific problem-solving, as well as helping design and refine this presentation. A true AI pair programmer in every sense.
Though it makes a lot of stupid mistakes, often!
Thank You!
Questions & Discussion